Blending old and new with RDS and AppSync
Blending old and new with RDS and AppSync
by Michael Woolsey

AWS AppSync plays an important part within the world of Amazon Web Services application development. Having the ability to quickly create and deploy a GraphQL API helps significantly with creating modern applications. GraphQL is an open-source data query language that seeks to work as an improvement over the traditional REST API, with the main selling point that it only ends up fetching exactly what it needs from the data source, whereas REST API’s can have the tendency to “over-fetch” or “under-fetch” data. While AppSync works incredibly well with AWS’s proprietary NoSQL database system DynamoDB, it doesn’t have as seamless of an integration with the Relational Database Service, which is Amazon’s managed SQL database offering. While DynamoDB works well for a lot of applications, SQL databases are still the preferred option for many solutions where the structure and relationships of data is important to be reflected in the database. I encountered the friction between AppSync and RDS during my development of the UBC CIC project Commit2Act, an application which makes extensive use of AWS AppSync. This blog post will serve as an introductory guide to AppSync and GraphQL, and will also instruct how to set up an AppSync API for an RDS database.
Table of contents:
An introduction to AppSync and GraphQL:
A GraphQL API works similarly in concept to a traditional REST API, a user will call the API endpoint with a request to either fetch data (a query) or modify data (a mutation) in a database, and the API will return either the data we wanted to fetch, or the modified data. For AppSync, for each call to the AppSync GraphQL API endpoint the query/mutation’s corresponding resolver is triggered, and this resolver essentially asks the data source to do something, such as fetching or modifying data. In our solutions with AppSync and RDS, a triggered resolver will pass along an SQL statement to a Lambda function, which will then execute the SQL statement on to the RDS instance. But more on that later. Inside of AppSync, there is a schema which acts like the skeleton for AppSync; it provides the structure that the API is built on. The schema contains many different types, and these types represent the different tables inside of the RDS instance. For an example, for a User table in our SQL database, if we have these data:
user_id | username | name | email | avatar
----------------------------------------------------------------
1 | michael | Michael | mikey@example.ca | example.png
2 | heisenberg | Walter | wwhite@gmail.com | null
Here is how the User type should be defined in the GraphQL schema:
type User {
user_id: Int!
name: String!
email: String!
avatar: String
username: String!
}Here, we are defining the 5 columns in the SQL Table as a type with 5 different fields, with each field corresponding to a column in the database (the fields are user_id, username, name, email, and avatar). Each type has a scalar type (also known as a data type in most other languages) which defines what kind of data each field represents. GraphQL only has a few different scalar types, and these are String, Int, Float, Boolean, and ID. Since these have less resolution than MySQL data types, a GraphQL String just means anything string based. So for example, data types in MySQL like TEXT, VARCHAR(255), and DATETIME are all represented by String in GraphQL. The ID scalar type is special, since it is essentially just a unique string meant to identify an object, and is not designed to be human readable. In our example case our database is using a unique integer to represent the id, so we will use the Int scalar type.
In the Schema Definition Language (SDL), an ‘!’ means that the field cannot be null (so here, the fields user_id, name, email, and username cannot have null values after a query or mutation is called that returns the type User).
It is also possible to define our own scalar types in the schema. These are defined as the following:
enum UserRoleInGroup {
owner
member
}These can be used exactly the same way as a String or Int inside of a type.
type GroupUser {
group_id: Int!
user_id: Int!
user_role: UserRoleInGroup!
}This means that user_role can only be the strings “owner” or “member”, and it cannot be null.
Queries
There are some special types defined within the Schema Definition Language, and the two most important to know about are the query type and the mutation type. These are defined in the schema as the following:
schema {
query: Query
mutation: Mutation
}This tells AppSync that the queries are located in the Query type, and mutations in the Mutation type.
A query is a kind of API call that only retrieves data. These can be thought of as essentially just SELECT statements. These statements will only read from the data source, and will not modify the data. Here is an example of how queries are defined in the schema:
type Query {
getTotalGlobalCO2: Float
getAllGroups: [Group]
getSingleGroup(group_id: Int!): Group
}The query type is defined the same way any other type would be defined. For each query that we want to write, the field will be the name of the query (Note: the convention for queries and mutations is to write the queries in camelCase, with the name starting with get), and the scalar type will be the data type that will be returned from the query.
For getTotalGlobalCO2, the field is getTotalGlobalCO2 and the scalar type is Float. When the getTotalGlobalCO2 query is called it executes the SQL statement SELECT SUM(SubmittedAction.g_co2_saved) AS totalCO2 FROM SubmittedAction WHERE is_validated=1, which will then get us back a float value. How this specifically executes the statement and returns the value will be described in the Resolvers section of this post.
The getAllGroups query demonstrates returning a non-standard scalar type, this query will return a list of Groups. An output may look something like:
[
{
"group_id": 10,
"group_desc": "Lorem ipsum dolor sit amet…",
"is_public": false,
"group_name": "Group 5",
"group_image": "https://d11qgrlajea.cloudfront.net/Group5.png"
},
{
"group_id": 18,
"group_desc": "Where something delicious is always cooking",
"is_public": true,
"group_name": "Los Pollos Hermanos",
"group_image": "https://d11qgrlajea.cloudfront.net/lph.png"
}
An important thing to note is that when executing a query (or mutation), you have to specify what outputs you want to receive. This is one of the strengths of GraphQL, as we only have to ask for exactly whichever fields we want to receive. For example, if we were to run the query:
getSingleGroup(group_id: 18) {
group_name
group_id
}The output would be:
{
"group_name": "Los Pollos Hermanos",
"group_id": 18
}
There is also a subscription type, which is similar to a query, but instead acts as a continuous live-updating stream of data through a websocket to ensure the most up to date data at any given moment. We won’t get into those today, but they are good to look into if you want to display low-latency real-time updates to data.
Mutations
A mutation is defined in a similar way to a query, however what makes mutations different is that they have the ability to modify data in the data source, similar to an INSERT, UPDATE, or DELETE operation in SQL. An important thing to note is that a mutation is still expected to return a value. Here is an example of some mutations:
type Mutation {
createUser(
name: String!,
email: String!,
avatar: String,
username: String!
): User
updateGroup(
group_id: Int!,
group_name: String,
group_desc: String,
group_image: String,
is_public: Boolean,
private_password: String
): Group
deleteQuiz(quiz_id: Int!): String
}For the createUser mutation, we are essentially passing in all of the different parameters required to define a User, however we do not need to pass in user_id since in the RDS instance we define user_id with the AUTO INCREMENT option, which will automatically generate a unique id for the User. The mutation will then return the created user, along with the new user_id. Only the name, email, and username fields are actually required to be inputted, the avatar is optional.
For the updateGroup mutation, the only variable that is necessary to input is the group_id, and all the other ones are optional. This lets us only have to actually input whichever fields we want to update.
For the deleteQuiz mutation, we only need to input the quiz_id of the quiz we want to delete, no other fields are necessary. For all the deletes I usually return a String. I do this because we can’t really return a deleted quiz, so I usually just pass back a string that’s along the lines of “Deleted quiz!”.
Testing queries and mutations
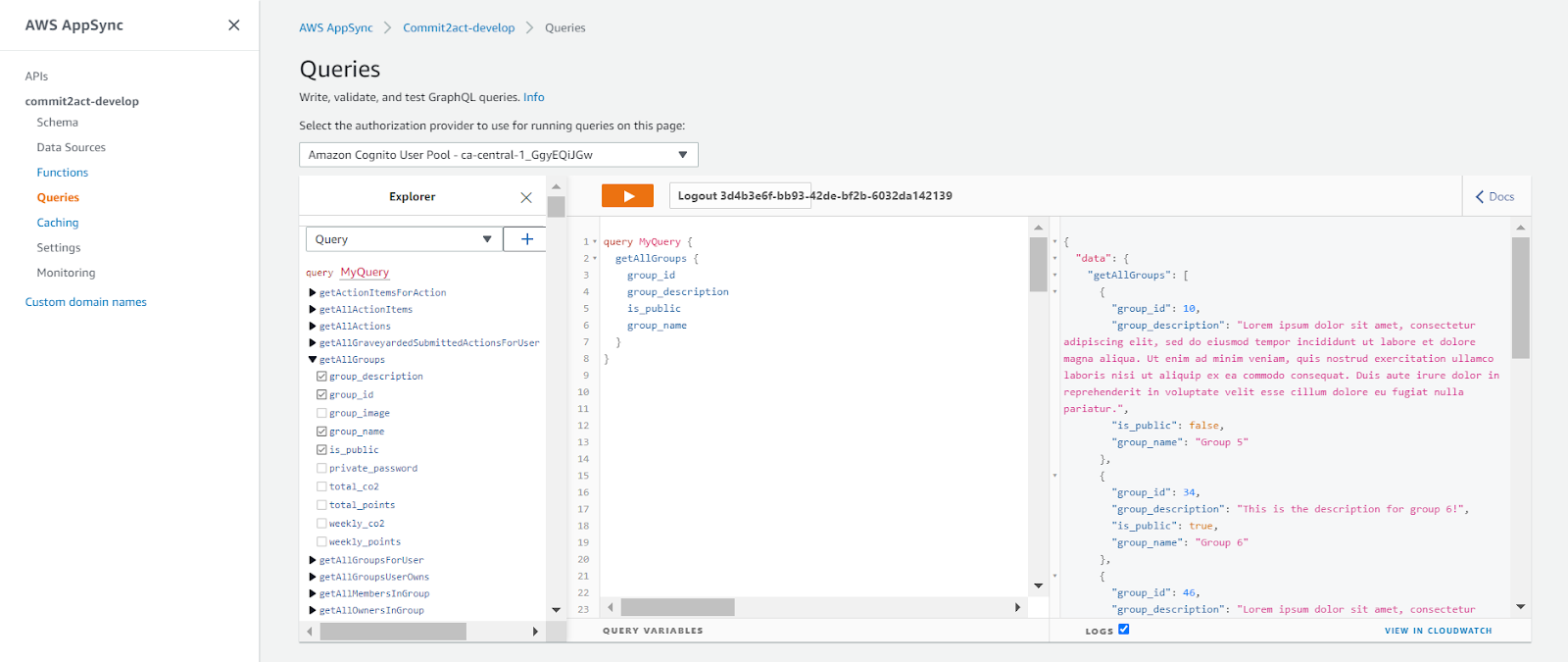
Testing is an important part of making new queries and mutations, and the easiest way to test them is through the Queries tab on AppSync. In the image above, we can see the module in the middle of the screen has 3 parts.
The left part lists all queries and mutations currently in the schema. When we select a query or mutation, we can see an option to select exactly which fields we want to be returned to us. A major advantage of GraphQL is that we do not actually need to return all the fields when making an API call, we only need to return whichever fields are important for us at the time. In the image, we have only selected the group_id, group_description, is_public, and group_name fields, so those are the only fields appearing in the resulting array on the right side of the screen.
In the middle of the screen, you can type out exactly the queries and mutations you want to test. When selecting a query or mutation on the left of the screen, this middle section is automatically populated with the statement that will be executed.
To execute a query or mutation, we just need to click the orange play button in the top middle of the screen. This will then ask us which query or mutation we want to run. The returned result will appear on the right. Before running, I recommend making sure the checkbox named LOGS is checked (located in the bottom right), as this will give you a quick link to access the CloudWatch logs for that statement’s execution, which helps with debugging when a query or mutation is acting not how you would expect. This hyperlink appears on the VIEW IN CLOUDWATCH text that appears after execution (NOTE: make sure logging is enabled in the Settings tab on AppSync).
Custom types
For the Commit2Act project, I found that there were plenty of situations where we would want to extend the schema beyond just types for each unique table. For example, it is possible we would want the result of two or more tables joined together as the response. When we start making more complicated queries and mutations, we will need to define custom types that don’t just correspond with just one table.
One example of this is the getUserStatsForGroup(user_id: Int!, group_id: Int!): UserGroupStats query. The UserGroupStats type is the following:
type UserGroupStats {
user_id: Int
group_id: Int
total_co2: Float
total_points: Int
weekly_co2: Float
weekly_points: Int
}Since in the frontend, we decided that having a single query that gets these metrics for a user in a group would be important, so I made a new type to return the values we actually need.
AppSync Resolvers
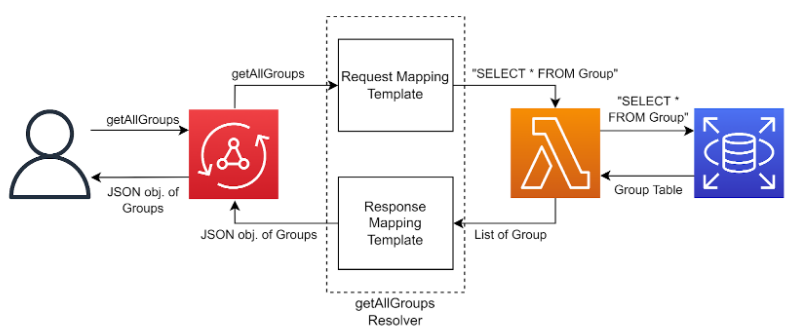
Resolvers are an extremely important part of AppSync to know about, since resolvers act as a mechanism to translate queries and mutations into statements our data source can interpret. There are many different ways to configure resolvers, but this guide will just describe the setup used for this project.
Creating and accessing resolvers

To create a new resolver for a query or mutation, first navigate to the Schema tab on the AppSync console. On the right of the screen, there will be a large section devoted to resolvers. Scroll down the list until you find the query or mutation that you want to make the resolver for. There should be a button called Attach next to the name of the query or mutation, and clicking that will bring you to the following screen with the resolver information.
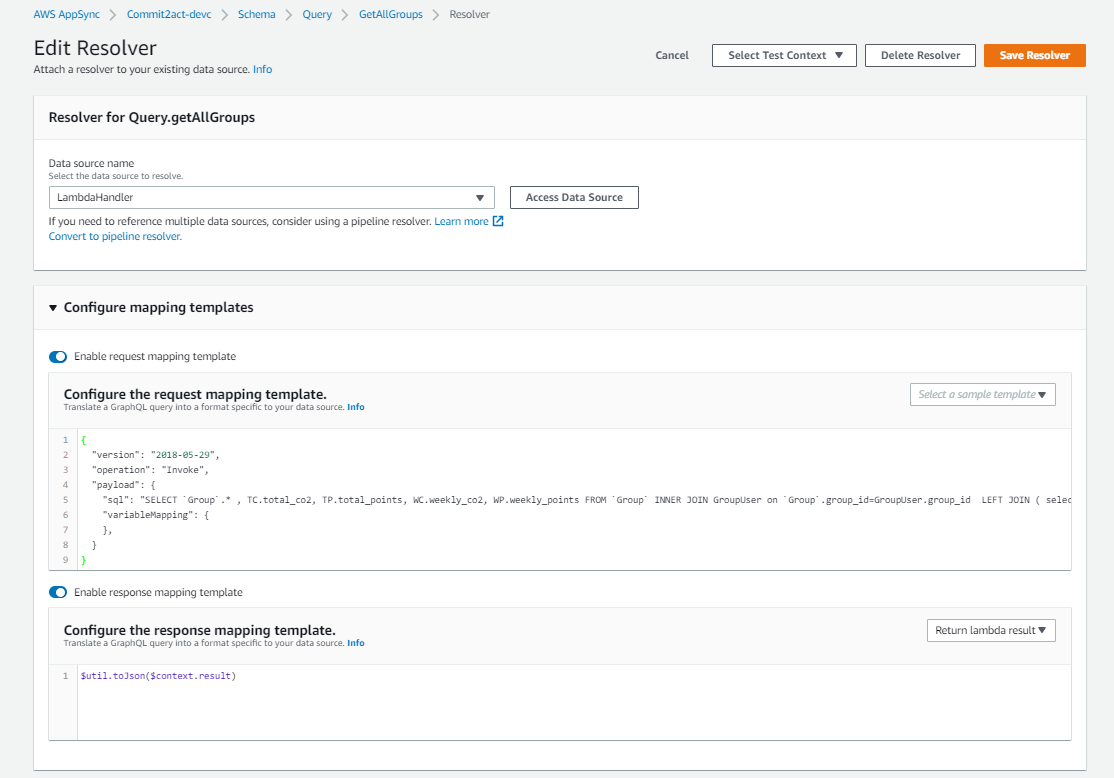
The first bit of information that is required to be entered is the Data source name. This is asking where exactly should AppSync look for the data when the query/mutation is executed. We are going to want to use a Lambda function as our data source. What exactly this Lambda function will look like will be explained in the next section of this blog post titled Connecting AppSync to RDS, however I believe it is important to first understand what exactly the resolvers are going to send to the Lambda, and how they operate.
Selecting the Lambda as our data source, we then see two toggles that we need to switch on, and these are Enable request mapping template and Enable response mapping template. These mapping templates are how the resolvers work, and they are written in VTL (Velocity Template Language), and while it is not essential to understand this language, it will be helpful in cases where more complicated resolvers are required.
After filling in values for both mapping templates, press the Save Resolver button in the top right to save the resolver. To modify the resolver in the future, scroll on the same right panel in the schema screen until you find the query/mutation you want to modify, then click on the text that says the name of the Lambda data source (you may have to scroll to the right on the panel to see the text).
NOTE: The AppSync console is awkward to work with at times. I have had several cases where I will just suddenly lose some of my resolvers that I was working on. The best way to avoid this is to only have 1 single tab for working on resolvers. Working on multiple resolvers at once can cause glitches as when you try to save one, it may overwrite the state of another. I do recommend making backups of your API as you go along, because you never know when something may go wrong. Since AppSync does not really have a version control system out-of-the-box, you can manually make a backup of your queries through the CLI command
aws appsync list-resolvers –api-id INSERT-API-ID-HERE –type-name Query > queries.txt
Repeat this command for mutations as well. Here we are just saving the result of list-resolvers into a text file, where we can see the mapping templates for each resolver. You may need to add the –profile INSERT-AWS-PROFILE-HERE argument in the command if you have multiple AWS accounts on your CLI.
Request mapping templates
The request mapping template is a way to transform the data received from the GraphQL query/mutation into a form that our data source can understand. Since our data source is a Lambda function, we need to transform the data into a JSON object. The payload JSON object will be passed to the Lambda function as an input after VTL has evaluated any logic in our resolver. There is a very specific format required for the request mapping templates so that the Lambda will execute correctly, and it is the following:
{
"version" : "2017-02-28",
"operation": "Invoke",
"payload": {
"sql": "SQL STATEMENT TEXT HERE",
"variableMapping": {
"key": $argumentfrominput
}
"responseSQL": "OPTIONAL FIELD, SQL STATEMENT TO BE EXECUTED AFTER THE FIRST sql IS RUN"
}
}This is the JSON object that the Lambda will receive. Here is a concrete example of how it looks for the addGroupMember mutation:
{
"version": "2018-05-29",
"operation": "Invoke",
"payload": {
"sql": "INSERT INTO GroupUser (group_id, user_id, user_role) VALUES (:1, :2, 'member')",
"variableMapping": {
":1": $context.arguments.group_id,
":2": $context.arguments.user_id
},
"responseSQL": "SELECT * FROM GroupUser WHERE group_id=:1 AND user_id=:2"
}
}The “sql” key contains the SQL statement we want to execute first. In this case, we want to insert into the GroupUser table a group_id, a user_id, and set the user_role to “member”. The group_id and user_id are arguments that are passed in from GraphQL, and how we actually get the values of these input arguments into the SQL statement is through the “variableMapping” JSON object.
variableMapping contains a key-pair combo for every user defined argument that we want to pass into the SQL statements. In VTL, the `$` symbol means the following text is a variable (or a special AppSync operation, which we will see later), and AppSync automatically populates each variable with the name $context.arguments.INPUT_VARIABLE_NAME with the inputted value for every variable with a value passed in to the statement. In the Lambda, we will iterate through variableMapping, and we will look for the first instance of each variable mapping key (for example, :1) inside of the “sql” string, and then it will replace the key with the corresponding value in variableMapping (if the passed in group_id was 10, then the first instance of :1 found in the sql string will be replaced with the value 10).
The same principle applies to the “responseSQL” key. This statement is used inside of mutations to get a return value back to GraphQL. The Lambda will execute this statement after the initial sql statement. The same variableMapping object will be applied to responseSQL.
NOTE: The value for “version” should not really matter, “2017-02-28” or “2018-05-29” work just fine
The contents of variableMapping will depend on exactly what the inputs to a query/mutation are. In the case where there are no inputs, we can just make it an empty JSON object. Here is an example from getAllSubmittedActions:
{
"version": "2018-05-29",
"operation": "Invoke",
"payload": {
"sql": "SELECT * FROM SubmittedAction",
"variableMapping": {},
}
}One really important thing to keep in mind when putting the variables in variableMapping is which scalar type the variable is will define how variableMapping will look. When the argument’s scalar type is a String, the VTL variable should be surrounded with double quotes. Here is an example for the query createSubmittedActionItem:
{
"version": "2018-05-29",
"operation": "Invoke",
"payload": {
"sql": "INSERT INTO SubmittedActionItem ( item_name, sa_id, input_value ) VALUES (:1, :2, :3)",
"variableMapping": {
":1": "$context.arguments.item_name",
":2": $context.arguments.sa_id,
":3": $context.arguments.input_value
},
"responseSQL": "SELECT * FROM SubmittedActionItem WHERE item_name=:1 AND sa_id=:2"
}
}
Above, the item_name argument is a String, so we have to wrap it with double quotes. The sa_id and input_value are both numerical, so we do not need quotes for them. A Boolean can be entered the same way as an Int or a Float.
It is also possible for the sql string to hold multiple statements, each separated by a semi-colon, which is useful in situations where you would want to insert into multiple tables at once.
Response mapping templates
A response mapping template acts in a similar way to its request counterpart, however this one will transform the returned values from the Lambda function into a format that GraphQL will be happy with. There are really only 3 different ways a response mapping template will look, and it just depends on what the returning type is.
If the returning type is a normal type not in an array (like the getSingleGroup query, it should return 1 object of type Group), the response mapping template should just be:
$util.toJson($context.result[0])This $util.toJson function is incredibly important for the response mapping templates, it essentially just turns the output from the Lambda into a format that GraphQL will be able to read. The $context.result[0] just means “get the first element from the result of the Lambda”, since the Lambda returns everything in the form of an array, [0] is important to include to get the return type to not be a list.
If the returning type is an array of a certain type (like getAllGroups, this returns type [Group]), the response mapping template will just look like
$util.toJson($context.result)
In the event that the return type is a scalar type (like in the query getTotalGlobalCO2 the return type is Float), the response mapping template will look a little more complicated, and uses a bit of VTL logic to work:
#if ($context.result[0].get("totalCO2"))
$util.toJson($context.result[0].get("totalCO2"))
#else
0.0
#endThis will return the float value for the SQL column totalCO2 from the statement SELECT SUM(SubmittedAction.g_co2_saved) AS totalCO2 from SubmittedAction where is_validated=1 if the value exists. If the value does not exist (i.e. the query returned null, which will happen if the SubmittedAction table does not have any actions where is_validated=1) we just return a value of 0.0.
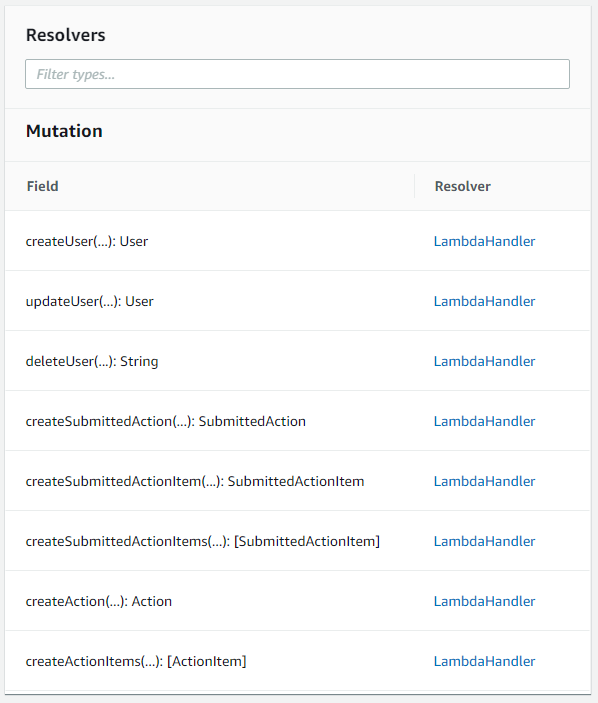
If you would like to take a look at more resolvers, feel free to look at the Commit2Act project. In our CloudFormation template we defined all of the resolvers we created, along with the schema.
Connecting AppSync to RDS
You may have noticed that earlier I chose a Lambda function as the data source for the resolvers. I made this choice because there is no native connection between AppSync and RDS like DynamoDB, so instead we will use a Lambda function to connect to RDS and pass along our SQL statement to the database.
The following is a Node.js 14.x Lambda function that connects to the database, iterates through the passed in SQL statements, and returns the result. Credit goes to Defodji Sogbohossou at Shine Solutions, as their work formed the basis for this Lambda code, however I have made some alterations.
const mysql = require('mysql');
let dbInit = false;function executeSQL(connection, sql_statement) {
// executes an sql statement as a promise
// with included error handling
return new Promise((resolve,reject) => {
console.log('Executing SQL:', sql_statement);
connection.query({sql: sql_statement, timeout: 60000}, (err, data) => { // if there is an error, it gets saved in err, else the response from DB saved in data
if(err) {
return reject(err);
}
return resolve(data);
} );
});
}function populateAndSanitizeSQL(sql, variableMapping, connection) {
// iterates through the variableMapping JSON object, and replaces
// the first instance of the key in the sql string with the value.
// Also sanitizes the inputs for the values
Object.entries(variableMapping).forEach(([key, value]) => {
let escapedValue = connection.escape(value);
// if in the GraphQL request, a user does not pass in the value of
// a variable required in the statement, set the variable to null
if (String(escapedValue).length == 0 || escapedValue.charAt(0) == "$") {
escapedValue = null;
}
sql = sql.replace(key, escapedValue);
});return sql;
}let connection;
connection = mysql.createPool({
host : process.env.RDS_ENDPOINT,
user : process.env.USERNAME,
password : process.env.PASSWORD,
database : process.env.DBNAME
});exports.handler = async (event) => {
// called whenever a GraphQL event is received
console.log('Received event', JSON.stringify(event, null, 3));
let result;// split up multiple SQL statements into an array
let sql_statements = event.sql.split(";");
// iterate through the SQL statements
for (let sql_statement of sql_statements) {
// sometimes an empty statement will try to be executed,
// this stops those from executing
if (sql_statement.length < 3) {
continue;
}
// 'fill in' the variables in the sql statement with ones from variableMapping
const inputSQL = populateAndSanitizeSQL(sql_statement, event.variableMapping, connection);
// execute the sql statement on our database
result = await executeSQL(connection, inputSQL);
}// for secondary SQL statement to execute, like a SELECT after an INSERT
if (event.responseSQL) {
const responseSQL =
populateAndSanitizeSQL(event.responseSQL, event.variableMapping, connection);
result = await executeSQL(connection, responseSQL);
}
console.log("Finished execution")
return result;
};In the Lambda settings we also need to create the environment variables RDS_ENDPOINT (the url of the endpoint you want to use), USERNAME (the username to connect with), PASSWORD (the associated password for the username), and DBNAME (what database to access, this depends on how you set up your database but this value is usually ‘sys’). You can also modify this code to store these attributes within the SSM Parameter Store.
In order to set up this as the data source, go to AppSync’s Data Sources tab for your API, and create a new data source. Give it a name (something like LambdaHandler), and set the type to AWS Lambda function. Select the region your Lambda is in, and then just select the ARN of the Lambda. You can choose to use a custom existing IAM role for this data source, but it usually is just better to let AppSync make the role for you.
Now you are done! You have now connected AppSync to RDS.
In conclusion
AWS AppSync is a very powerful tool for your application. This guide only scratches the surface of what this service can do, so I implore you to try playing around with it! There are many other things you can delve into to help with your apps, such as adding a Web Application Firewall for additional security and rate limiting, using Cognito User Groups to restrict certain queries/mutations to particular users in your app, adding error handling to the response mapping templates, or using more complicated VTL logic to enhance the functionality of your resolvers. In any case, you now have a good scalable backbone for your app that you can enhance to meet whatever your needs are!
References
DynamoDB vs Amazon RDS – The Ultimate Comparison by Nishani Dissanayake
GraphQL vs. REST: What You Didn’t Know by Adil Sikandar
Serverless GraphQL AppSync API with RDS by Defodji Sogbohossou