Tapestry Project – Migrating a graph WordPress plugin from a Relational Database to a Graph Database
Tapestry Project – Migrating a graph WordPress plugin from a Relational Database to a Graph Database
By Aayush Behl
Tapestry is an open-source online learning platform that allows users, authors, viewers, students, and instructors to collaborate in the development of interactive, associative, and multi-modal content. Its first version is based on WordPress, which is an extremely popular CMS (Content Management System) that helps users build websites/blogs that leverages a wide variety of plugins to enhance content in different ways. The ease of developing a WordPress plugin has led many developers to create open-source plugins that can use the MySQL database to store content in a custom manner. However, using a relational database may not always be the best way to store data.
This blog post demonstrates the process of moving a MySQL plugin to a native Graph Database using AWS Neptune.
Tapestry Tool – A WordPress Plugin
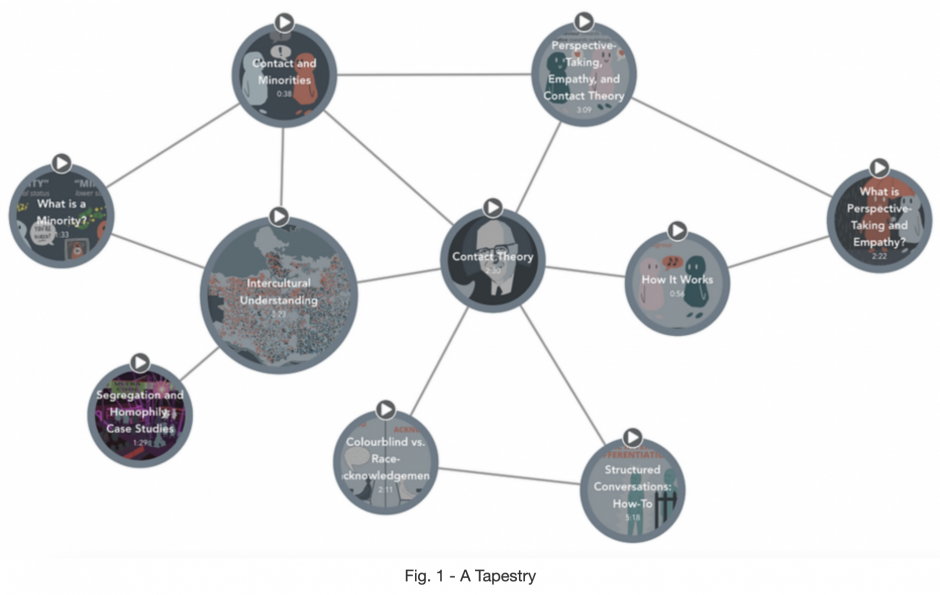
The Tapestry Tool WordPress plugin allows creating non-linear, collaborative, and interactive content. This allows users to create graphs where each node stores content (e.g. text, videos, etc.) and nodes with related information can be connected to each other via edges/links. An example can be seen in Fig. 1.
The plugin also allows granular access control to the nodes. For example, a viewer may not be allowed to see node X until he has completed node Y or they might not be allowed to see the node before a certain date and time. An editor, on the other hand, can access the nodes at all times. Users can have access to a node if either they specifically have permissions to do so or if their role (for e.g. administrator, authenticated, or custom roles) has permissions to do so. To accomplish this, the MySQL version of the plugin leverages tables that store user permissions, user progress and lock/unlock conditions for each node.
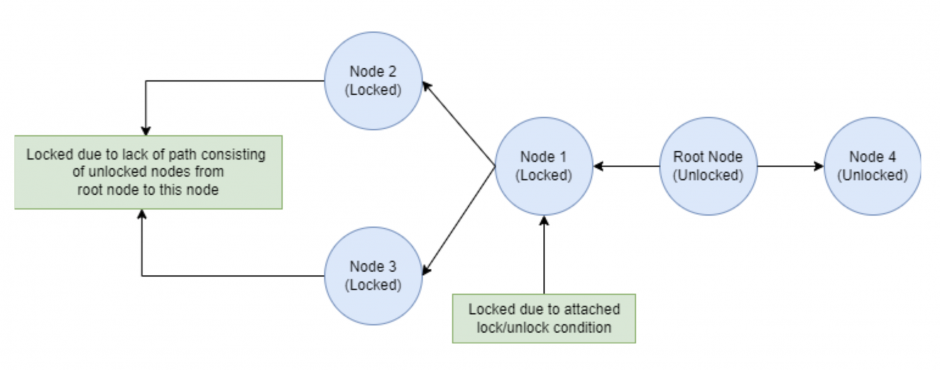
Moreover, whether or not a node X is unlocked also depends upon whether or not a path exists from the root node to the node X such that all nodes on this path are also unlocked (see Fig. 2). This calls for Depth-First Search (DFS) or Breadth-First Search (BFS) while checking which nodes to filter out.
Relational Database Approach
Although a Tapestry is an actual graph, the plugin uses the MySQL database provided by WordPress. It stores the metadata of different entities used by the plugin into the wp_postmeta table. There are three different types of entities stored in the wp_postmeta table, each differentiated from the other by their meta_key. These three types are tapestry, tapestry_node and tapestry_node_data. The last two are simply used for storing data related to a single node of the graph and have little to do with the actual structure of the graph. What is interesting is the data labeled tapestry, which represents a single graph or tapestry, because it represents the actual structure of the graph.
The wp_postmeta table contains serialized PHP strings (a storable representation of objects, like JSON) instead of multiple columns per table and all data is stored in these strings. They are found in the meta_value column of the table.
Each piece of data in the wp_postmeta table has one attribute called meta_value that stores objects as serialized PHP strings. This allows for entities with different numbers of attributes to be stored in the same table.
The figure below (Fig. 3) consists of three tapestry_nodes, each renamed to match their postId in the WordPress MySQL database for ease of understanding.
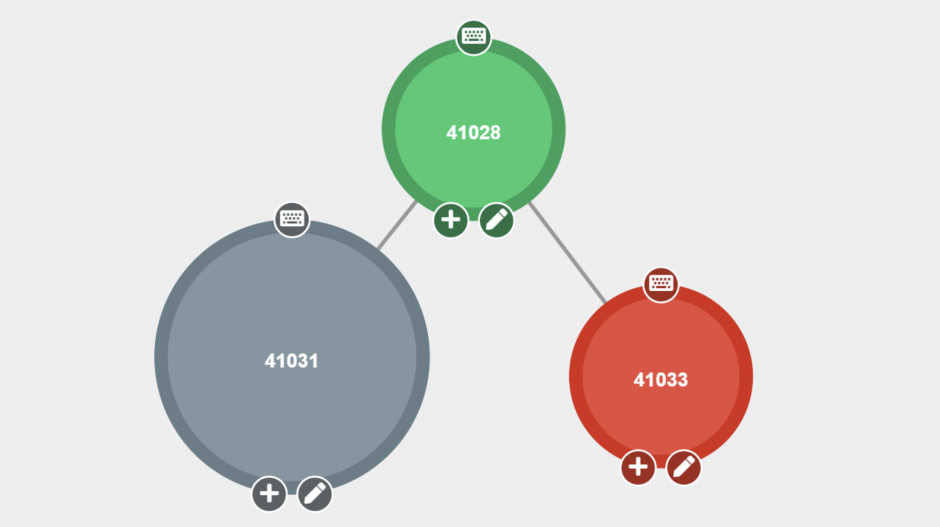
The snippet below shows the PHP data structure that can be found in this tapestry’s meta_value.
stdClass Object
(
[nodes] => Array
(
[0] => 41028
[1] => 41031
[2] => 41033
)
[links] => Array
(
[0] => stdClass Object
(
[source] => 41028
[target] => 41031
[value] => 1
[type] =>
[addedOnNodeCreation] => 1
)
[1] => stdClass Object
(
[source] => 41028
[target] => 41033
[value] => 1
[type] =>
[addedOnNodeCreation] => 1
)
)
[settings] => stdClass Object
(
[tapestrySlug] => tapestryexample
[title] => TapestryExample
[status] => publish
[backgroundUrl] =>
[autoLayout] =>
[showAccess] => 1
[showRejected] =>
[showAcceptedHighlight] => 1
[defaultPermissions] => stdClass Object
(
[public] => Array
(
[0] => read
)
[authenticated] => Array
(
[0] => read
)
[contributor] => Array
(
[0] => read
)
[subscriber] => Array
(
[0] => read
)
)
[superuserOverridePermissions] => 1
[analyticsEnabled] =>
[draftNodesEnabled] => 1
[submitNodesEnabled] => 1
[permalink] => http://localhost/wordpress/tapestry/tapestryexample/
)
[rootId] => 41028
)The array called nodes stores the postIds of all the nodes contained within the tapestry (41028, 41031, and 41033). The array called links stores objects where each object represents an edge/link from the node with postId source to the node with postId target. For example, the edge links[0] represents the edge between node 41028 and node 41031. The field rootId is the postId of the root node of the graph. This object represents the graph structure of the tapestry.
Everytime a user tries to load a tapestry, the PHP plugin code first loads this data structure into memory. A breadth-first search traversal is then applied to the graph to filter out nodes based on locked/unlocked status and access permissions. This step is actually quite complex. It involves checking the user progress, the user-level permissions and the role-level permissions for each node. And all of these pieces of information are stored at different locations. Finally, after the filtration, all the tapestry_node and tapestry_node_data metadata corresponding to the nodes of the tapestry is loaded. This gives us the complete tapestry.
The Challenge with the Relational Database Approach
From the description above, it is evident that extra effort is being put into using serialized objects to represent a graph in a MySQL database, then loading it all back into PHP, and then traversing it while figuring out the access restrictions for each node. That seems like a lot of work! So, I used a graph database to better facilitate these operations.
Migrating to a Graph Database
Since WordPress does not normally integrate with graph databases, there was no easy way of using a graph database for the plugin. In my approach, I used Amazon Neptune – a graph database service, fully managed by AWS.
The solution architecture
The overall cloud infrastructure for the graph database version of Tapestry is represented on Fig. 4. WordPress does not need to be running on AWS. Amazon API Gateway expose endpoints that allows wordpress to invoke AWS Lambdas (in a microservices fashion) to access Neptune, which can only exist in a VPC (Virtual Private Cloud) on AWS;
Let us look at the different parts of the architecture to see how graph database queries can take place from the plugin.
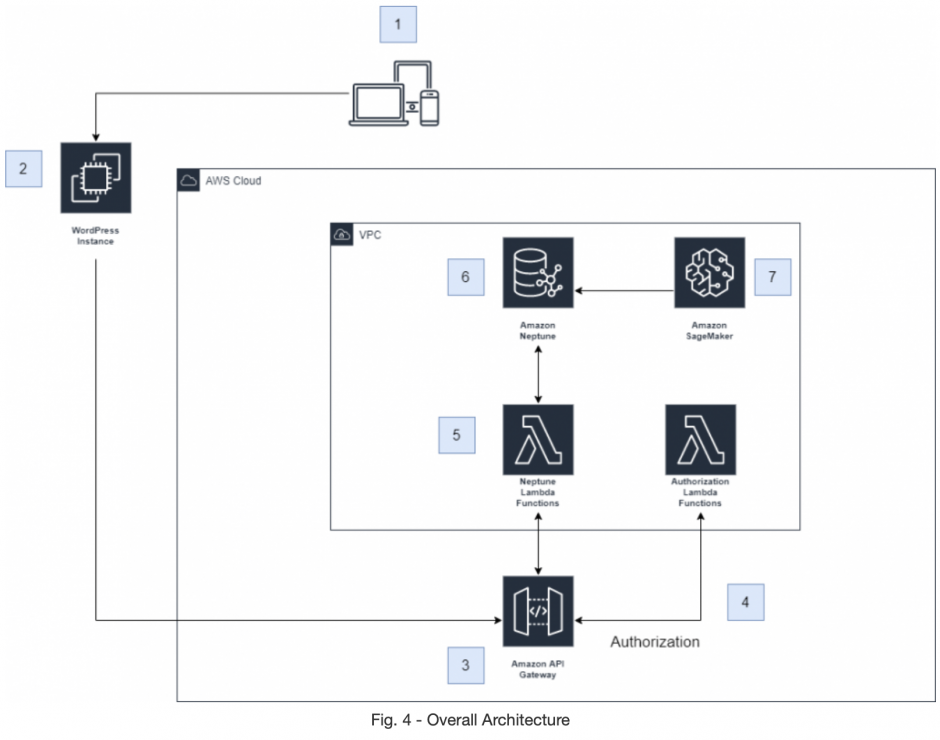
- Users access Tapestry through WordPress.
- Tapestry’s PHP code contains functions to make HTTP GET, POST and DELETE requests using curl. These functions can be found in this file. The plugin makes HTTP requests to the HTTP API Gateway (3) depending upon the user’s action. For example, if a user adds a node to a Tapestry, the plugin makes a POST request at the ‘/addNode’ route.
- The HTTP API Gateway is responsible for triggering the database-interacting AWS Lambda functions (5). But, we cannot have an open API Gateway endpoint which anyone can access from anywhere on the internet. That’s why we use a Lambda authorizer (4) to authorize that the call is made by the plugin itself.
- An AWS Lambda function is used as an authorizer. It stores a security key in its environment variables. All HTTP requests made to the API Gateway (3) must contain this security key in the authorization header (as seen in the code snippet for httpPost). Otherwise, access to the database-interacting Lambda functions (5) will be denied.
- Different routes of the HTTP API Gateway trigger different Lambda functions and each Lambda function has different interactions with the Amazon Neptune database. Fig. 5 shows the different routes and Lambda functions for Tapestry. Notice that the Lambda functions must exist in the same VPC (Virtual Private Cloud) as the Amazon Neptune graph database (6). Each Lambda function uses a Node.js runtime with drivers for Gremlin, the graph traversal language used for querying the database in this project.
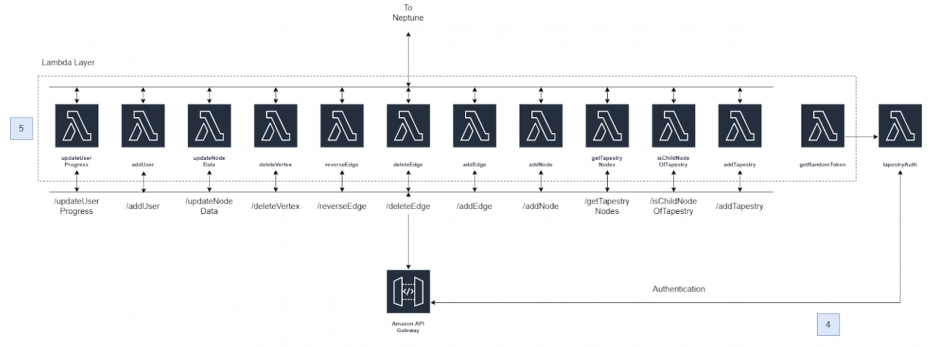
The Lambda functions used in this project can be found here. Each Lambda function first sets up the connection to the database and then executes the query. The database set-up code is common to each Lambda function and so has been stored as a separate file in the Lambda layer. The database set-up conforms to AWS’ guide for setting up Lambda functions for use with Amazon Neptune.
- The Amazon Neptune database instance is the graph database that our plugin interacts with by means of HTTPS requests to the API Gateway
- Amazon Neptune allows the use of an optional Amazon SageMaker notebook to run queries directly in both Gremlin and SPARQL traversal languages.
Storing Data in the Graph Database
Now that there is a way to interact with the remote graph database, all that’s left to do is to define a schema – a model that defines what types of edges connect which kinds of nodes to each other and what attributes each node/edge stores. For ease of understanding, Fig. 6 shows a simplified diagram that shows how the Tapestry in Fig. 1 is represented in the Amazon Neptune graph database. Note that this figure just shows the nodes and edges that capture the Tapestry’s graph structure.
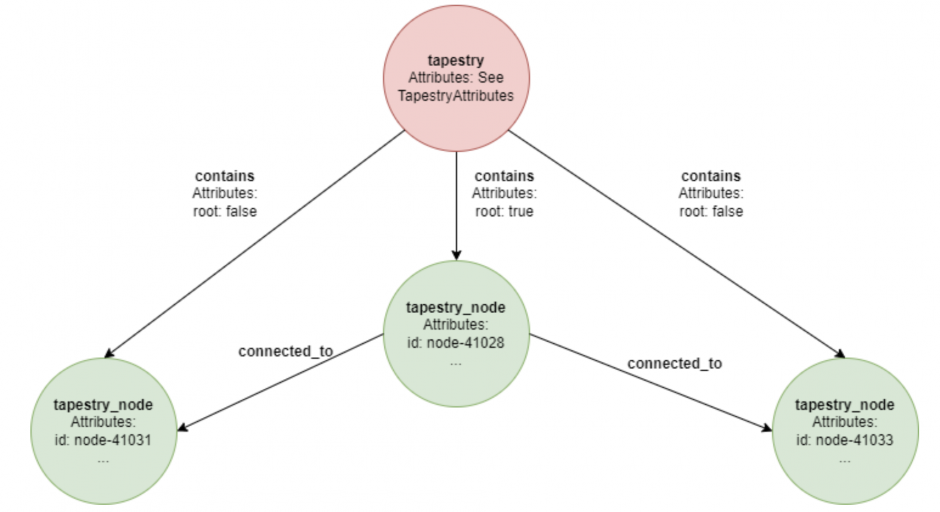
Fig. 7 shows the entire graph database schema for a Tapestry in general. It contains other nodes and interactions like users and conditions as well.
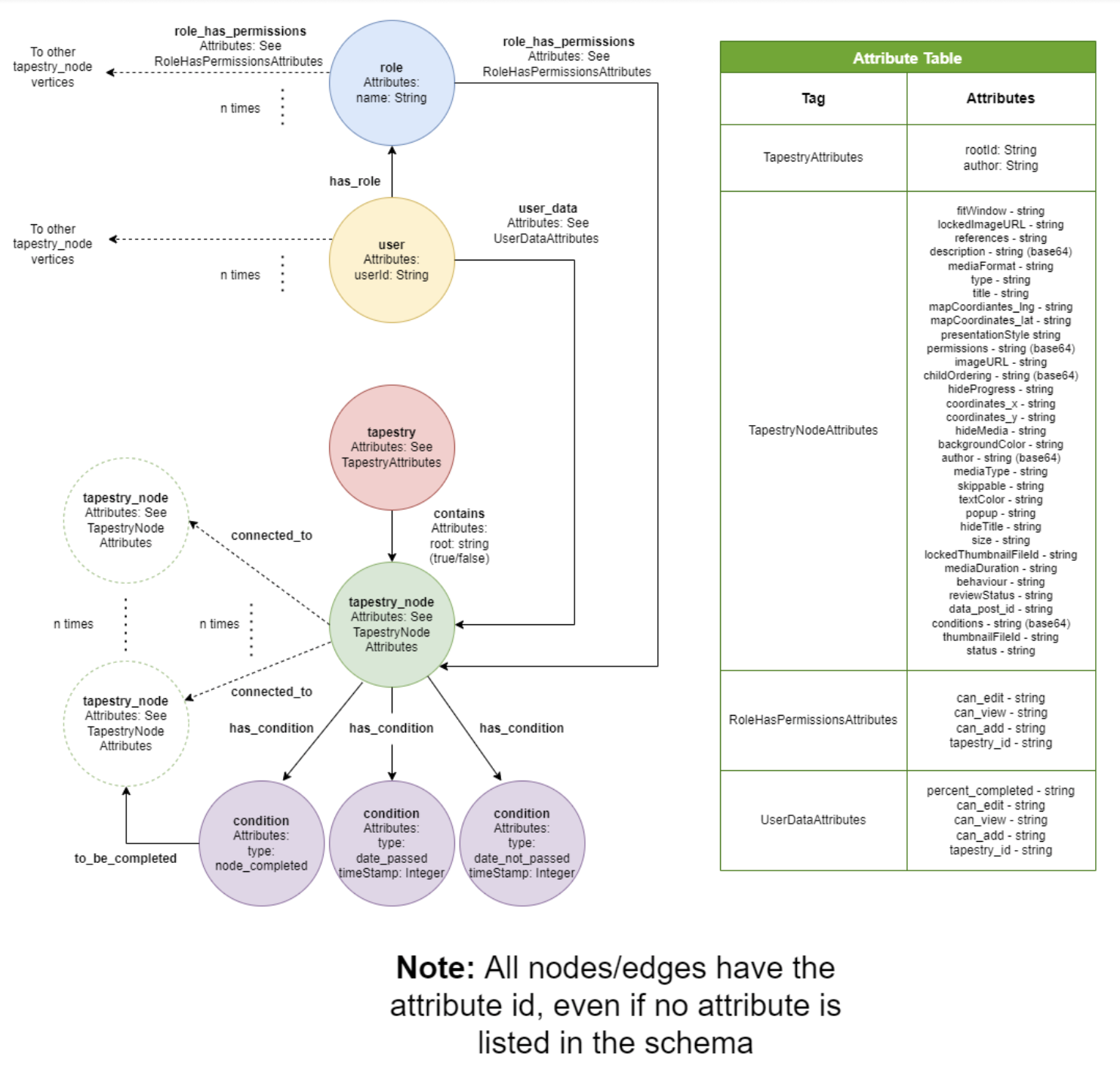
Let’s look at each part of the schema one by one:
- tapestry: This type of node acts as an umbrella for all the tapestry_node vertices contained within the tapestry. It has outgoing contains edges to tapestry_node vertices which signify that the target tapestry_node is contained within the tapestry.
- tapestry_node: This type of node represents an actual node of a tapestry, and is connected to other nodes of its kind through connected_to edges. The nodes that can be seen in Fig. 1 are all of the type tapestry_node, and all the edges are connected_to edges. This node stores most of the metadata of a node as well. It also has outgoing edges to conditions vertices to check locked/unlocked state and incoming edges from user and role vertices to check user-specific and role-specific access restrictions for the node respectively.
- condition: A node to represent locked/unlocked unconditional for a tapestry_node. Can be of three kinds – node_completed (checks whether user has completed watching the contents of another node), date_passed (check if a given date and time has passed), and date_not_passed (check if a given date and time has not passed)
- user: A node that represents a user that is using the plugin. Has outgoing edges to tapestry_node vertices to track access and user progress.
- role: A node that represents a role, for example, administrator, subscriber, publisher, etc. It is used to give a group of users the same access permissions. The outgoing role_has_permissions edges going out to tapestry_node vertices are what actually store permissions.
The above schema when used with Amazon Neptune allows tapestry graphs to be stored as graphs instead of objects. Once we have a graph in the database, we can create AWS Lambda functions with Gremlin drivers to create all sorts of query executors. One such complex Lambda function used in the project allows users to filter out nodes based on access and locked/unlocked state by traversing through the graph starting at the root node. This means that when a user makes an API call to GET a graph, Lambda uses Gremlin to return just the filtered-out nodes to the plugin and the plugin PHP does not have to do a breadth-first search on the graph anymore.
The following code snippet gives a simplified example of the Gremlin query that can traverse a graph in a Breadth or Depth-First Search manner starting at the root node, and drop any nodes (and their children if no other paths to them exist) that fail to fulfill a certain criteria.
var nodes = g.V(id)
.repeat(__.choose(__.hasLabel('tapestry'),__.outE('contains').has('root','true').inV(),__.both('connected_to')).simplePath()
// filter begins
.where(__.values('status').is('publish'))
// filter ends
.as('nodes')).emit().until(__.select('nodes').count().is(0)).dedup().fold().next();In this Gremlin code, all tapestry_node nodes (and their children if no other paths to them exist) get dropped if the status attribute of that tapestry_node is not set to publish. So basically, a connected component of nodes where each node has the status attributeset to publish is returned by this query. This is a very simple application of the traversal query. The actual code uses a much more complex filter to get the nodes that the user has access to. It can be found here.
Conclusion
That is how I changed Tapestry to leverage a Graph Database. The plugin still uses the relational database to some extent. For example, the bulk data of a tapestry_node, which stores the content of each node, is still stored in the MySQL database. But this information is needed only when a user clicks on a node to view its content. Loading the entire graph structure does not require involvement of the relational database and so there is no performance hindrance. After moving to graph databases, I found a performance improvement for large (700+ nodes) Tapestry graphs. However, smaller Tapestry graphs are still faster with relational databases. So if a Tapestry user wants to increase the scale of their Tapestry graphs, it is probably a good idea to migrate to Amazon Neptune!
The WordPress version of the plugin can be found here.
The cloud infrastructure code and deployment guide for it can be found here.