Digitizing Medical Forms

Project phases
The IBD Centre of BC has automated data ingestion from dictated consultation letters, improving the efficiency of the digitization process.
Overview
The IBD Centre of BC provides care for patients with Inflammatory Bowel Disease, and records patient information in the form of PDF dictated letters as well as paper documents. Manually inputting this information into the Electronic Medical Record (EMR) is a time-intensive and inefficient process. The resources spent on this process could otherwise be used to focus on other areas of work, such as analysing the data to generate insights and optimize patient care.
This prototype solution streamlines the ingestion of medical information from patient files, which is an important step towards both efficiency and the ability to run analytics on the collected data to understand the impact that medical decisions have on individual patients.
Approach
The prototype uses two managed machine learning services, Amazon Textract and Amazon Comprehend Medical, to extract the relevant information from dictated consultation letters.
During the patient consultation, physicians create letters within text fields by dictating notes into their EMR software. Doctors can then process those files through the solution and extract the relevant medical information into an industry-standard, digital format; therefore the data collected is stored in a data lake, and doctors can then analyze it with their own tools and find the information that they need quickly.
This data lake enables physicians to access and analyze patient information extracted from the analyzed documents using AWS Analytics and visualization tools; it also allows future integration with the FIHR interoperability standard.
Link to solution on GitHub: https://github.com/UBC-CIC/referral-medical-letter-processing
Supporting Artifacts
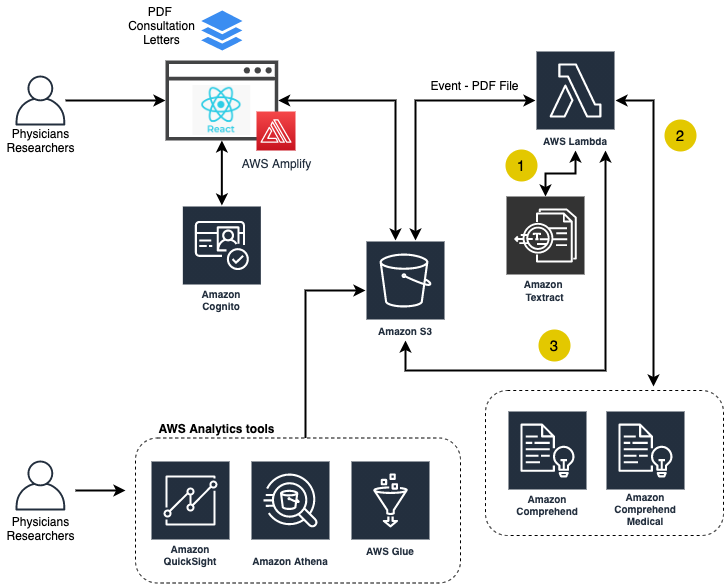
Architecture Diagram
Technical Details
In the backend, the PDF letters are processed by Amazon Textract to extract the text from the dictated PDF letters. The information extracted is then processed by Amazon Comprehend Medical to identify and classify medical information such as medical conditions, medications, dosages, tests, treatments, and procedures, and protected health information. To better capture the patient context, the application also utilizes regular expression patterns to obtain time-related context.
1- AWS Lambda receives an event when a new PDF file is uploaded via the WebApp, and sends it to Amazon Textract to process.
2- Once Amazon Textract returns the digitized version of the PDF, it is sent to the NLP Amazon Comprehend Medical and Amazon Comprehend to extract key phrases and to extract health data.
3- The results are processed and categorized using the JSON format. The files are saved into Amazon S3.
Over time, as more data is collected the physicians have the option to execute Amazon Analytical tools to analyse and visualize the data. During the POC development, the team explored using AWS Glue, Amazon Athena and Amazon QuickSight for visualization.
FAQs
Q: How can I view and verify the data output?
A: The results are saved into the S3 bucket in JSON format. The tool allows the user to visualize the JSON structure at the WebApp.
Q: How is patient privacy maintained?
A: When the files are processed, we redact all personally identifiable information recognized by Amazon Comprehend Medical. We also replace the patient number by a unique identifier.
Q: Will there be a learning curve to use this solution?
A: This tool is simple and only does one job; it allows physicians to upload PDF files to extract health information.
Q: If there’s a problem, who do I contact?
A: The CIC developed the prototype as open-source as-is. There is no support or improvement on the solutions after its release.
Q: How do I get started with using this solution?
Q: You can go to the repository and then use the deployment guides in the readme.
Header Photo Credit – Image by rawpixel.com
About the University of British Columbia Cloud Innovation Centre (UBC CIC)
The UBC CIC is a public-private collaboration between UBC and Amazon Web Services (AWS). A CIC identifies digital transformation challenges, the problems or opportunities that matter to the community, and provides subject matter expertise and CIC leadership.
Using Amazon’s innovation methodology, dedicated UBC and AWS CIC staff work with students, staff and faculty, as well as community, government or not-for-profit organizations to define challenges, to engage with subject matter experts, to identify a solution, and to build a Proof of Concept (PoC). Through co-op and work-integrated learning, students also have an opportunity to learn new skills which they will later be able to apply in the workforce.
