Student Advising Assistant

Project phases
The Faculty of Science Advising office at UBC collaborated with the UBC Cloud Innovation Center (CIC) to leverage large language models (LLMs) and generative AI to build a prototype with the goal to improve the advising quality and student experience. The prototype takes information from the Academic Calendar and other reliable UBC sources to provide around-the-clock service that responds to inquiries. The application conveys key information in a conversational manner, in the effort to minimize confusion for some students.
Approach
Answers to a subset of questions and inquiries received at Science Advising can be found in the Academic Calendar but for some students, this process can be difficult to find or hard to interpret.
Focusing on the specific needs of Science students, the Science advising office and the UBC CIC designed a solution that generates a conversational response that draws on relevant information from the UBC Calendar and web content by the Faculty of Science, enhancing accessibility and readability of the information. Responses come from extractions of the Academic Calendar in the data ingestion/processing data pipeline stage. Specifically, the data processing script ensures important contextual information is not lost in the extraction process. The system can perform preprocessing and splitting of documents to improve the application’s understanding.
One key component to the answer generation of the prototype is the LLM. By default, the system uses Vicuna 7b LLM published by lmsys. Vicuna is used because the model is one of the top LLMs in terms of quality performance. Additionally, Vicuna is cost-effective because of its limited parameters compared to other model counterparts, and is open-source and viable for commercial use.
Screenshots of UI
Home Page
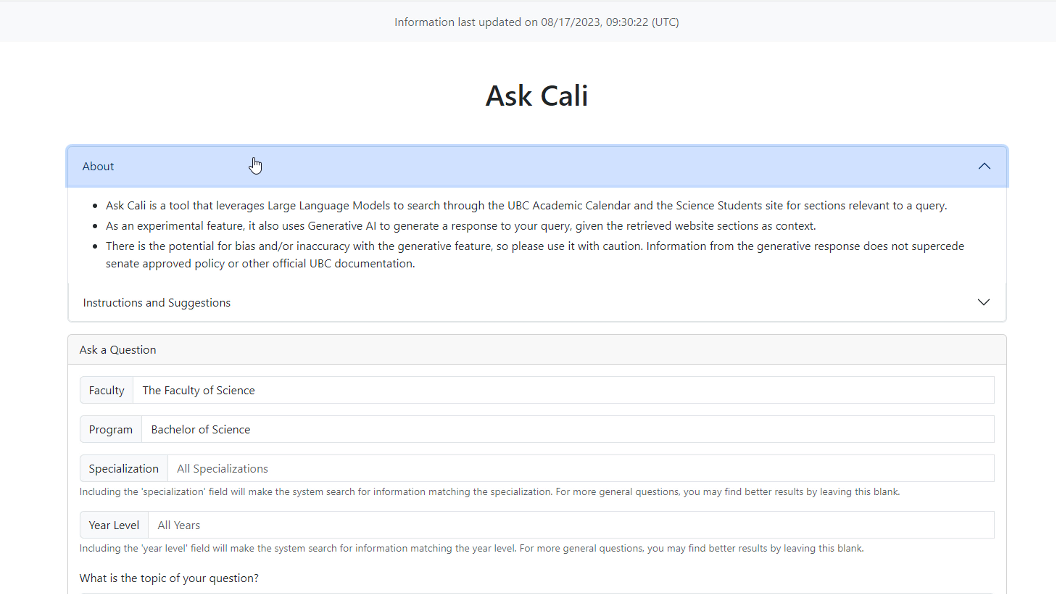
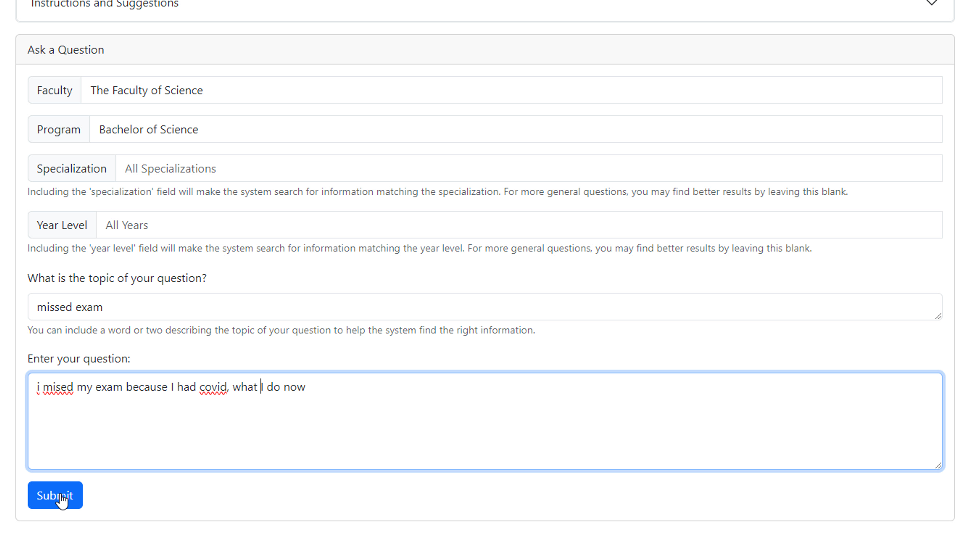
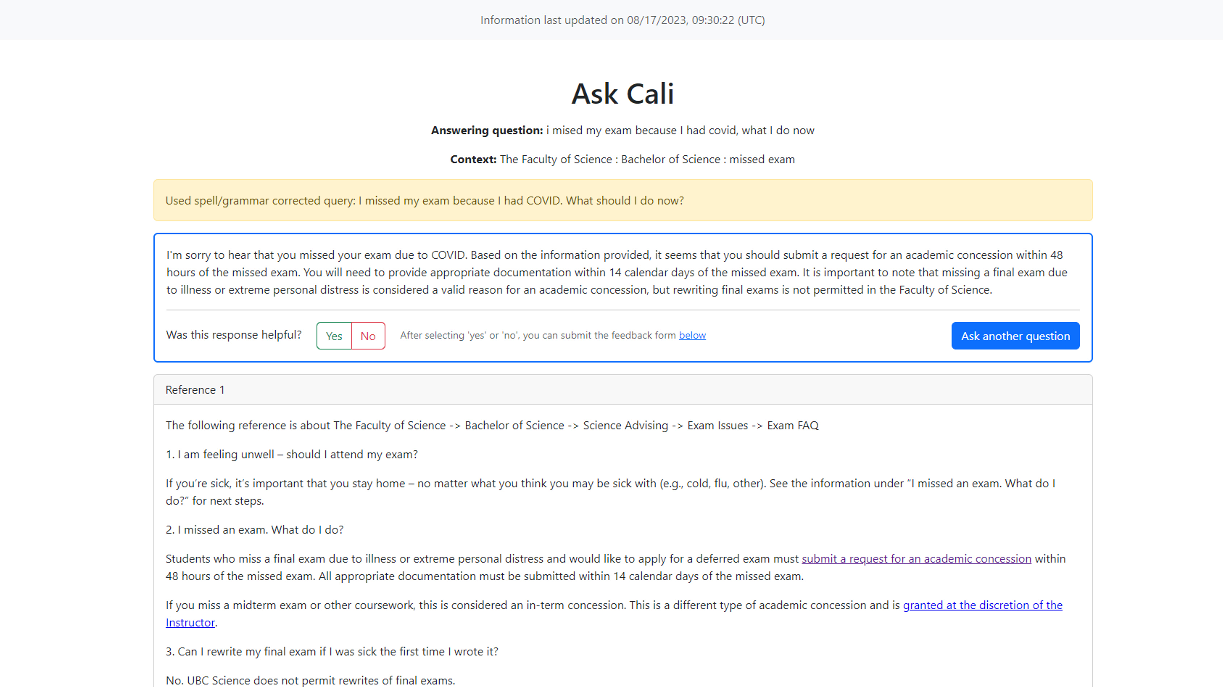
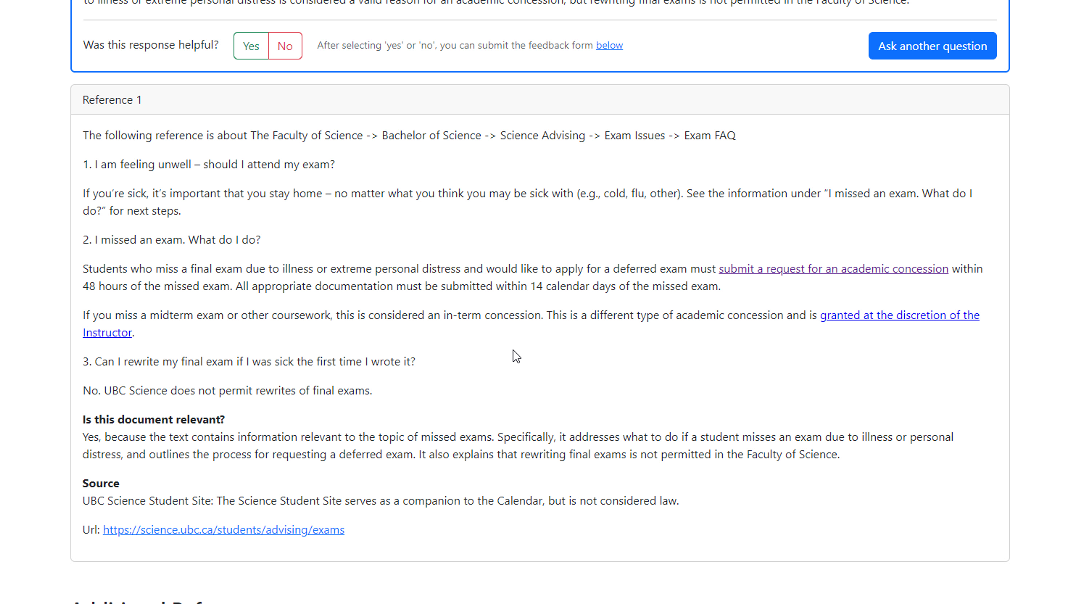
Answer Page
Technical Details
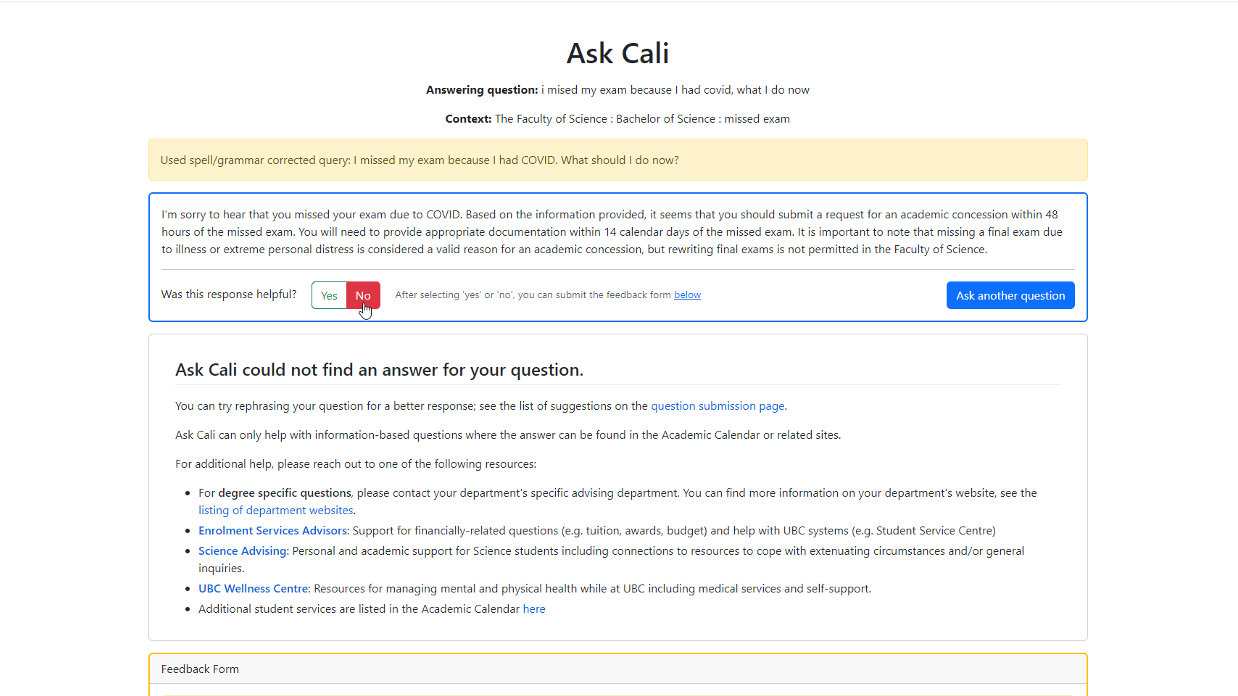
Students can interact with the frontend of the prototype to obtain answers to their inquiries, while the backend is the foundation of how question-answering works using generative AI, LLMs, and AWS. The frontend can appropriately react to user text regardless of grammar and/or spelling mistakes. In turn, the application can output relevant sections of UBC repositories in response to the question. Alternatively, the backend can be manually configured, so that admins can update the application and its prompts. The data ingestion pipeline enables admins to update repositories and is extensible to other repositories.
- The data ingestion / processing step scrapes the websites that the Admin specifies as information sources, then segments and preprocesses the contents for use by the question answering system.
- The question answering system consists of the frontend UI, where users can enter a question, and the backend machine learning models which retrieve the preprocessed content from the previous step to generate an informed answer.
Both components are explained below (expand + to see more detail).
Data Processing
Website scraping
The pipeline recursively downloads all child pages of the web pages specified in the configuration file. It keeps track of any redirects that occur, so that the processing step can identify link relationships between pages. It imposes a wait time between page downloads, as not to overburden the target websites.
Preprocessing
Once the scraping step is completed and the HTML pages are downloaded, the preprocessing step needs to clean unnecessary elements, extract the text content, and split the text into smaller chunks. The text needs to be chunked since the embedding models and LLMs require input text to be below a certain length.
Processing information for the purpose of student advising has some unique challenges, which the preprocessing step helps to address.
Contextual information in titles
There may be many sections of text from the included websites that appear similar when taken out of context, but actually apply to different faculties or programs. In these cases, the context is often given by the hierarchical structure of web pages, or even the hierarchical structure of titles within one webpage.
The data processing script keeps track of both types of titles and stores the information with each extract, so that the context is not lost. It identifies these titles within web pages in a configurable manner by html attributes.
Intelligent chunking with HTML and sentence awareness
Common text chunking techniques will convert html page contents into text, and then indiscriminately chunk the text, thereby losing valuable information that the html tags and structure provide. The data processing pipeline leverages html tags to split pages by topic, and splits text by section or paragraph whenever possible.
When a paragraph is too long, it uses spaCy to identify sentences and split the paragraph on a sentence boundary. This improves the embedding quality , since text extracts are more likely to stick to a single topic. It also improves answer generation, since it reduces the likelihood of reference extracts being cut off and thus losing information.
Table understanding
The Academic Calendar and other UBC information sources present a lot of information using non-free-text formats such as tables, which presents difficulty since LLMs are mostly trained to understand free text.
Some models are trained to answer questions over tables (models tested were TAPAS, TAPEX, and Markup LM), but these did not demonstrate satisfactory understanding of the tables common in the Academic Calendar, such as degree requirements tables.
As a result, the data processing step includes some table conversion functions to convert tables into sentences for better interpretability for LLMs. It includes some custom conversions for some types of tables in the Academic Calendar, and fallback conversions for generic tables.
Footnotes
Additionally, many tables use footnotes, indicated by superscripts within table cells. These footnotes could contain valuable information for interpreting the table, but may be cut off from the table with normal chunking techniques. The data processing step identifies footnotes indicated by superscripts in tables, and injects the footnote text into the processed text from the table so that footnote information is not lost from the chunked extracts.
Extract relationships
The processing step also keeps track of the relationships between extracts. ‘Parent’ extracts are associated with their hierarchical ‘children’, and these children are ‘siblings’. Any extract that contains a link to another extract also has a relationship to the target of the link. These link relationships take redirects into account. The relationships are stored in a graph data structure.
Currently, the question answering system does not leverage this information, but it could be valuable for future avenues of development that might take the relationships into account for better document retrieval.
Embedding
To support the question answering system’s document retrieval by semantic search, the text extracts are ‘embedded’ using the all-mpnet-base-v2 model. The model converts free text into dense vectors in a high-dimensional space, where the vectors represent the topic and meaning of the text.
Since a disproportionate amount of the ‘meaning’ of an extract is expressed by its titles as opposed to its actual content, the embedding step takes an unusual approach. For each extract, it embeds the ‘parent titles’ (the titles of parent web pages), ‘page titles’ (the titles leading up to an extract within a particular page), and the extract’s text individually, and then concatenates the resulting embeddings to create a longer vector. As a result, when the question answering system performs semantic search over these vectors, the titles have a large impact on which extracts are returned. This is very helpful in the context of student advising, where it is essential that the system returns the right extracts for a student’s faculty/program/etc.
Vector store
After computing the embeddings for each extract, the system uploads them to a vector store, which is a database designed to store vector embeddings. The system supports two choices of vector stores: RDS with pgvector, or Pinecone.io (see the definition terms below for details).
Both services can perform similarity search, hybrid search, and metadata filtering. RDS is more integrated with the AWS CDK and thus easier to deploy, while Pinecone offers a free-tier hosted service which is sufficient to contain up to 50,000 extracts. Both services are scalable.
The system uploads the vector embeddings with a set of metadata such as titles, text content (un-embedded), and url.
Question Answering
At the frontend of the question-answering system, a user enters a question, and may include optional additional context (i.e., faculty, program, specialization, year level, and/or topic).
Document retrieval
Semantic search
The system combines the user-inputted context with the question and embeds the text. The embedded text is sent to the vectorstore to perform a search for semantically similar extracts using the embedded query. The semantic search filters on metadata for faculty and/or program, if provided, so that only extracts within the user’s selected faculty and/or program will be returned. If the user includes their specialization and year level, this is included in the query used for semantic search, but the system does not strictly filter extracts on these fields.
See below for more details depending on the chosen retriever: pgvector or Pinecone.
RDS with pgvector
If the admin chose to use the pgvector retriever, then the embedded query is sent to the RDS DB and compared with all vectors in the DB by cosine similarity search. If the user provides their faculty and/or program, only entries matching the faculty and program are returned.
Pinecone.io
If the admin chose to use the Pinecone retriever, then the system also computes the BM25 sparse vector of the query, then sends both the sparse and dense (embedded) vectors for the query to Pinecone servers via the Pinecone API. Pinecone performs hybrid search over the vectorstore, by combining the dot product similarity scores of the sparse and dense vectors. The advantage of the hybrid search is that it takes into account both semantic similarity (dense vector) and keyword similarity (sparse vector).
LLM filter
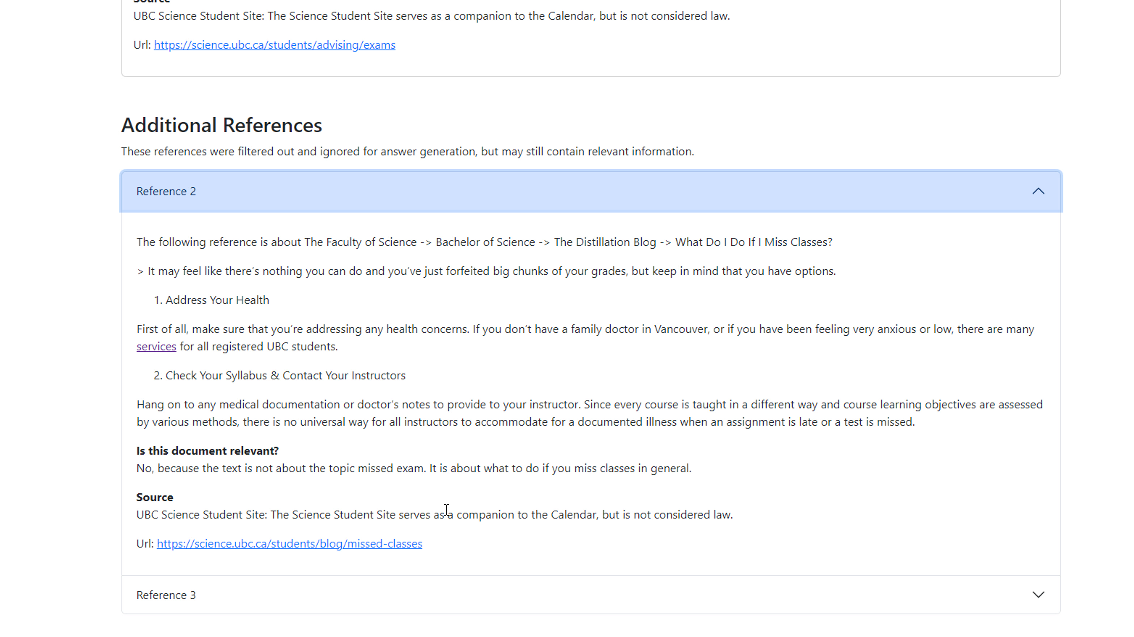
The documents that the retriever returns are the most semantically similar to the user’s question, but this does not necessarily mean they will be relevant to answer the question. The system then performs a second level of filtering using the LLM, by prompting the LLM to predict whether each extract is relevant to answer the question or not. If not, it is removed from the pool. This step helps to remove irrelevant information and reduce hallucinations in the answer generation step. Depending on the LLM model used, the LLM may respond to the prompt with an explanation in addition to its yes/no answer. The system will record and display the reasoning if given.
Context zooming
If the filter step removes all returned documents, then the system removes some of the provided context and redoes the semantic search, effectively ‘zooming out’ the context, in case the answer lies in a more general section of the information sources. For example, a student in a particular program may ask a question where the answer lies under the general University policies, rather than in the pages specifically for their program. By zooming out the context, the system can retrieve the relevant information.
Architecture Diagram
Step-by-step
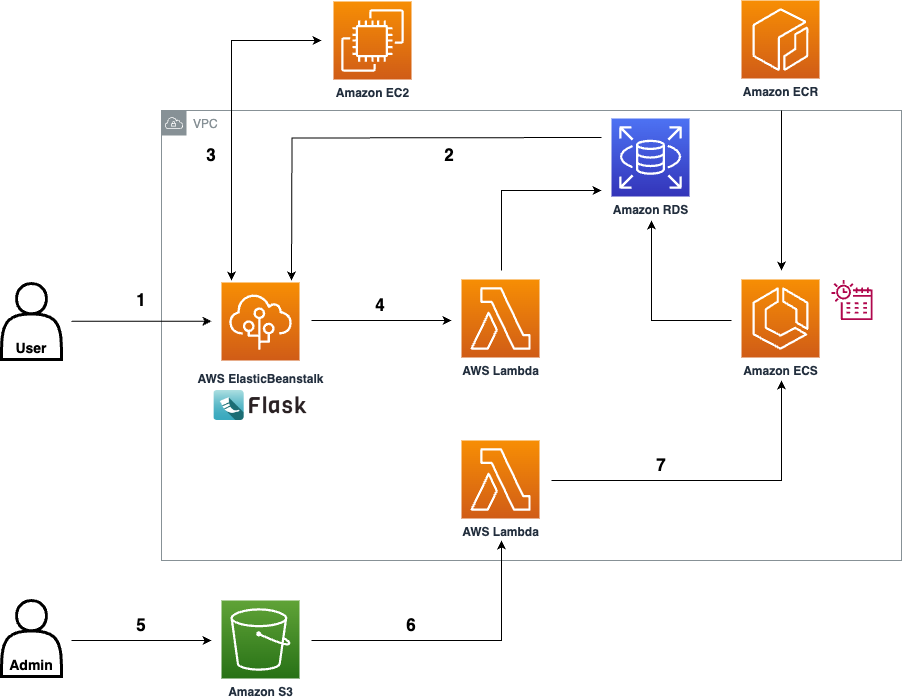
- A user (eg. a student) interacts with the web UI of the application hosted on AWS Elastic Beanstalk, and submits a query.
- Using semantic search over the embedded documents in the Amazon RDS PostgreSQL database, the app fetches documents that are most closely related to the user’s query.
- The app invokes a HuggingFace Text Generation Inference Endpoint hosting a LLM on an EC2 instance, prompting it to respond to the user’s query using the retrieved documents from step 2 as context. It then displays the response and the reference documents to the user in the web UI.
- The system logs all questions and answers, storing them in the Amazon RDS PostgreSQL database by making a request to an AWS Lambda Function as a proxy. Users can provide feedback to help improve the solution, which is also stored in the Amazon RDS PostgreSQL database using the AWS Lambda Function.
- The diagram illustrates the case where documents are stored in Amazon RDS. In the case that the system is using the Pinecone retriever, the app would instead make a request to the Pinecone.io API.
- The diagram illustrates the case where documents are stored in Amazon RDS. In the case that the system is using the Pinecone retriever, the app would instead make a request to the Pinecone.io API.
- When an Admin wants to configure the underlying settings of the data processing pipeline (eg. website scraping settings), they can modify and upload a config file to the predetermined folder on an Amazon S3 Bucket.
- The S3 Bucket triggers an invocation of an AWS Lambda Function to start a Task with the container cluster on Amazon ECS.
- This container cluster starts a Task that first performs web scraping of the configured websites, then processes the pages into extracts, and computes the vector embedding of the extracts. Finally, it stores the embeddings in the Amazon RDS PostgreSQL database (with pgvector support enabled). The Task is also scheduled to run every 4 months by default with a CRON-expression scheduler. An Admin/Developer can modify the schedule on-demand via the ECS console.
- The diagram illustrates the case where documents are stored in Amazon RDS. In the case that the system is using the Pinecone retriever, the Task would instead send the embedded extracts to the Pinecone API.
- The diagram illustrates the case where documents are stored in Amazon RDS. In the case that the system is using the Pinecone retriever, the Task would instead send the embedded extracts to the Pinecone API.
To potentially refine the system and for administrative purposes, the solution incorporates user feedback, which can later be reviewed and changed by the admin. Additionally, references are included to improve the reliability of the prototype. The open-source solution is maintainable and scalable because the system utilizes AWS resources.
Link to solution on GitHub: https://github.com/UBC-CIC/student-advising-assistant
Visuals
Infographic
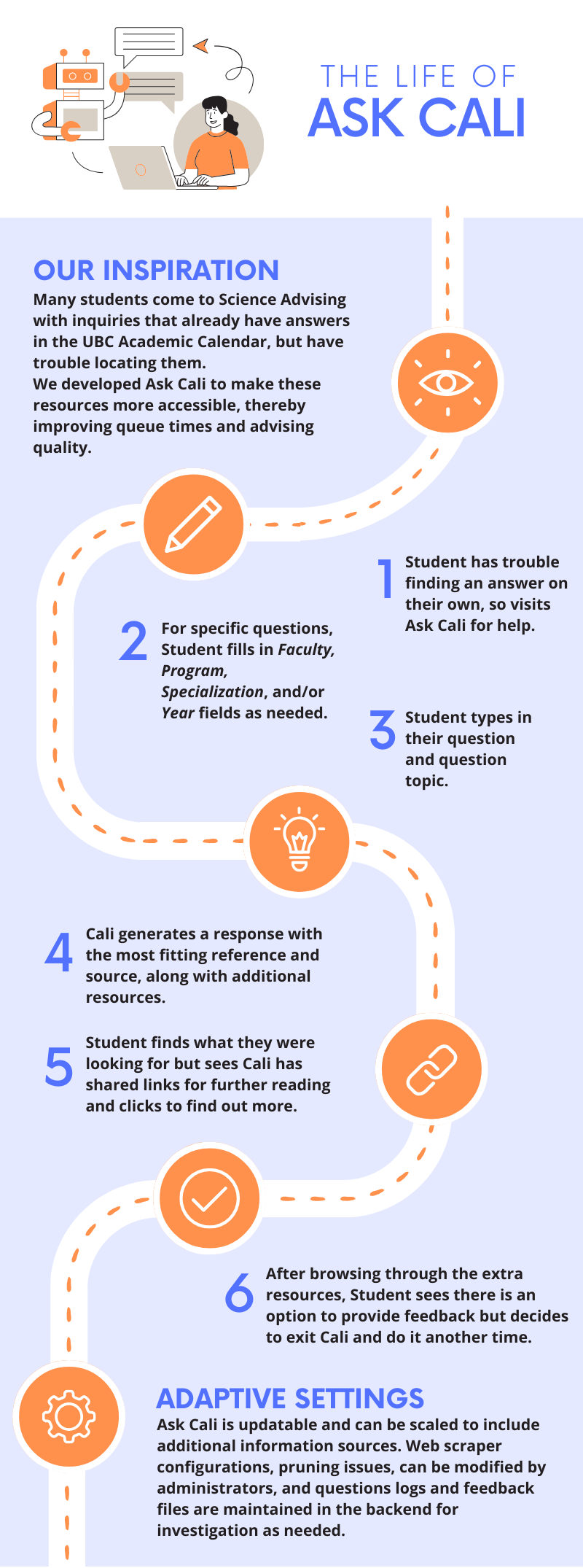
Demo Video
Acknowledgements
Photo by Jennifer Herrity
About the University of British Columbia Cloud Innovation Centre (UBC CIC)
The UBC CIC is a public-private collaboration between UBC and Amazon Web Services (AWS). A CIC identifies digital transformation challenges, the problems or opportunities that matter to the community, and provides subject matter expertise and CIC leadership.
Using Amazon’s innovation methodology, dedicated UBC and AWS CIC staff work with students, staff and faculty, as well as community, government or not-for-profit organizations to define challenges, to engage with subject matter experts, to identify a solution, and to build a Proof of Concept (PoC). Through co-op and work-integrated learning, students also have an opportunity to learn new skills which they will later be able to apply in the workforce.
