Automating Large-Scale Data Extraction from Archival Documents: University of Toronto Mississauga Department of Economics
Researchers at the University of Toronto Mississauga’s Department of Economics build a database of trade information with the help of automatic data extraction.
Overview
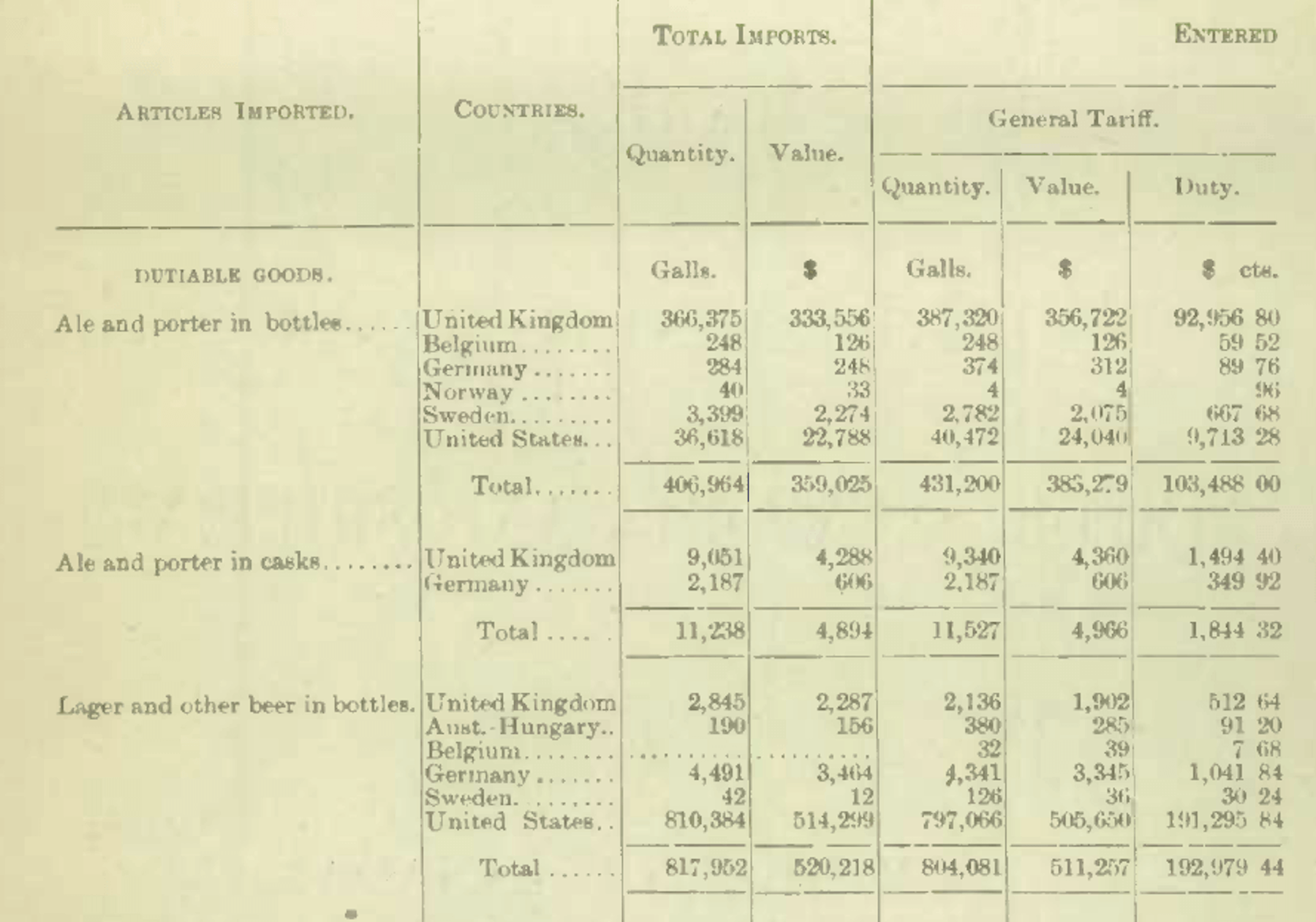
Today, the University of Toronto Mississauga (UTM) Department of Economics researchers rely on manual work to input tabular-data about trade information, scanned as PDF files from the Government of Canada’s historical repositories. Canadian academics will leverage the results of this project to better understand Canadian trade patterns from 1900 to 1939. However, manually inputting the data proved inefficient and cumbersome.
The Department of Economics at UTM partnered with the UBC CIC to modernize this process, to increase the quality and quantity of research, and to help with the creation of large Developmental Economics datasets. This solution helps economists answer the key question of how they can conduct research that involves a high volume of data collection in a cost- and time-effective manner. Enhanced and automated research processes free up valuable research funds that can be leveraged to increase research opportunities for students and to ease budgetary constraints. Overall, this project is a major step in bringing private sector solutions to academic institutions.
Approach
The University’s goal is to build one of the most comprehensive trade databases of Canadian trade from 1900-1939, by analyzing 30,000-50,000 pages of data. The collection of data required one person working part-time for twelve months to manually transfer 900 pages of data from PDFs into Excel. Currently, the researcher would have to find the tables and use a split screen monitor to enter data in an Excel spreadsheet. This process is not ergonomic or economic, as it prolongs the time and money needed to create datasets that are fit for further analysis.
This project was started in 2015 and the professor has been searching for an automated solution ever since, due to the sheer quantity of data that needs to be input. When trying to use Optical Character Recognition (OCR) on the documents, the researchers couldn’t make sense of the data retrieved, as often the tabular-format data spanned multiple pages and required manual intervention in order to properly make use of the information. It was easier to manually input the data than to reformat the results from OCR.
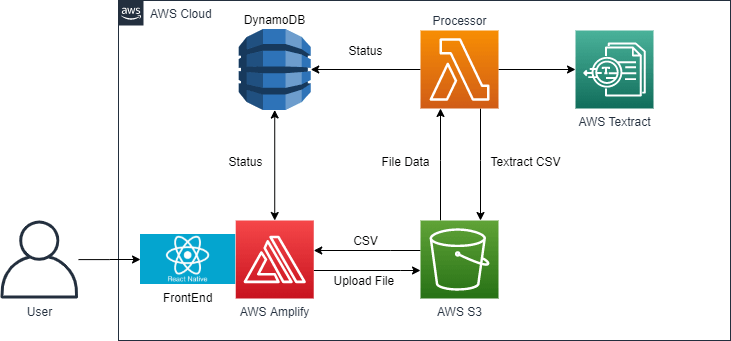
The UBC-CIC team built a prototype using Amazon Textract, AWS Lambda, Amazon S3, Amazon DynamoDB, AWS Amplify and Amazon Cognito. The solution demonstrates the ability to scan tabular-formatted data from the PDF files, which span multiple pages. The result is saved in comma-separated-values (csv) format. This process eliminates the tedious manual process of gathering information, and provides a consistent mechanism to obtain the data. The researchers are able to specify pages from which to extract data, and filter results based on accuracy.
All former British colonies organize their data in the same manner and Canada is no different. Because of this, this solution will be leveraged to collect data on all former colonies to better understand global trade patterns. We will start with Canada, and later move to analyze England, Australia, New Zealand and other domains. Because of this research, we will be able to better understand the economic impact of conflicts like World War One on the development of international markets.
Link to solution on GitHub: https://github.com/UBC-CIC/tabular-formatted-document-parser
Supporting Artifacts
During the Innovation Workshop, a fictional Press Release and nonfictional Frequently Asked Questions are drafted. This is a tool that is used to define the solution and why it matters to the customer. The Storyboard is a series of frames designed to illustrate the problem and the impact of the solution visually.
Architecture Diagram
Technical Details
PDF files, taken from historic records, can be difficult to decipher and result in errors even with OCR. To increase the accuracy of the solution, the team implemented a pre-processing step for the PDF. The individual pages that are requested from the PDF are converted into enlarged images for higher resolution using a python module. The images are then individually sent to AWS Textract for table detection through synchronous API calls. The data returned by Textract is parsed and formatted before saving it as a CSV file in an S3 instance.
On the frontend, researchers can set the pages to be scanned and confidence level of the data. The confidence level is associated with the degree of confidence for each data point returned by Textract. It acts as a threshold for filtering any results that have a low degree of confidence. A higher confidence threshold would return only the more accurate results, but the table would have fewer data points. From testing, the team recommends starting with a threshold of 50 and changing the value depending on the quality and type of the document.
A DynamoDB table is used to keep track of the status of the upload and conversion into CSV. The processor lambda function will set the status of the specific request to either Success or Error.
Press Release
A link here for the press release.
FAQs
Q: What is the recommended confidence level that I should start out with?
A: We recommend starting with a confidence level of 50 and modifying it depending on the results. If more accurate results are needed, increase the confidence, and vice versa.
Q: Can I set page ranges, or odd and even pages?
A: Yes, there is an option when uploading the document for setting page ranges, as well as odd or even pages.
Q: How accurate is the data output?
A: The accuracy of the data output depends on the quality of the original document. The solution does try to raise the quality of the document by converting it into high resolution images.
Q: Can it recognize other languages?
A: The solution is dependent on Amazon Textract, which currently recognizes English, Spanish, French, Italian, Portugese and German.
Q: Does it work with different kinds of tables and page orientation?
A: Yes, the solution will work for various tables and orientations.
Q: How does it get updated?
A: To update the backend, the lambda function code is located in the index.py file. Any updates must be pushed to the lambda function using the lambda.sh script. The frontend uses AWS Amplify and React, and updates can be pushed to a GitHub repo connected to the Amplify console.
Q: What is the infrastructure needed?
A: The AWS infrastructure required for the solution is AWS Amplify and Amazon Cognito for frontend and Amazon S3, AWS Lambda, Amazon DynamoDB, and Amazon Textract on the backend. This infrastructure is automatically created through the Amplify Console when the project gets deployed. For updates, a machine with the same virtual environment as Python3.8 in AWS Lambda is required.
Q: Is it scalable to other projects?
A: The solution is scalable as the backend is a standalone function and can be modified for form or general text detection.
Q: How much does it cost?
A: AWS uses pay as you go pricing and the cost is proportional to the consumption. Some services at AWS that we may use in this solution have a free requests per month utilization. The pricing utilization can be found at the service page at AWS. For example, follow some of the price of some of the solution’s components:
Amazon Textract – First 1 Million pages $0.001665
AWS Lambda – First 1 Million executions for free:
128 MB lambda – $0.0000000021 per 1ms
Amazon S3 – First 50 TB / Month $0.025 per GB
About the University of British Columbia Cloud Innovation Centre (UBC CIC)
The UBC CIC is a public-private collaboration between UBC and Amazon Web Services (AWS). A CIC identifies digital transformation challenges, the problems or opportunities that matter to the community, and provides subject matter expertise and CIC leadership.
Using Amazon’s innovation methodology, dedicated UBC and AWS CIC staff work with students, staff and faculty, as well as community, government or not-for-profit organizations to define challenges, to engage with subject matter experts, to identify a solution, and to build a Proof of Concept (PoC). Through co-op and work-integrated learning, students also have an opportunity to learn new skills which they will later be able to apply in the workforce.